Not All Failures Deserve a Second Chance
Designing a Selective Retry Policy

Retry logic is one of those things that feels simple until it isn’t.
You add @Retryable, set maxAttempts = 3, and move on. Everything works — until the system happily retries a validation error three times, re-publishes a message that was never going to fit in Kafka, or quietly fails to retry something that actually was transient.
At that point, retry logic stops being resilience. It becomes noise with a delay.
This post describes a pattern we introduced to prevent that kind of misconfiguration from ever becoming a production problem: a selective retry policy that makes retry intent explicit and centrally defined.
What Spring Retry Already Gives You
Spring Retry’s SimpleRetryPolicy allows exception-class-based configuration:
Map<Class<? extends Throwable>, Boolean> retryable = new HashMap<>();
retryable.put(SocketTimeoutException.class, true);
retryable.put(ValidationException.class, false);
new SimpleRetryPolicy(3, retryable, true);
This works — but only at the class level.
In practice:
A single
ApplicationExceptionmay represent multiple failure modes.Configuration becomes scattered across services.
There is no protection against marking the same exception as both retryable and non-retryable.
Retries are not about exception structure.
They are about failure semantics.
The Core Insight: Failures Have Meaning
Broadly speaking:
Transient failures
Temporary issues — network blips, timeouts, infrastructure instability.
Retries help.
Permanent failures
Invalid input, malformed payloads, authentication failures.
Retries waste time.
Retry logic should understand that distinction.
Step One: A Typed Exception with an Error Enum
Instead of proliferating exception classes, introduce a single typed exception:
public enum ErrorType {
VALIDATION_ERROR,
SERVICE_CLIENT_ERROR, // 4xx
SERVICE_SERVER_ERROR, // 5xx
MESSAGING_ERROR,
AUTHENTICATION_ERROR,
UNKNOWN_ERROR
}
public class ApplicationException extends RuntimeException {
private final ErrorType type;
public ApplicationException(ErrorType type, String message) {
super(message);
this.type = type;
}
public ApplicationException(ErrorType type, String message, Throwable cause) {
super(message, cause);
this.type = type;
}
public ErrorType getType() {
return type;
}
}
Now the exception carries semantic intent.
The retry policy no longer needs to infer behaviour from class names or messages.
Step Two: The Selective Retry Policy
SelectiveRetryPolicy extends SimpleRetryPolicy and introduces:
retryable exception classes
non-retryable exception classes
retryable error types
non-retryable error types
strict validation against overlap
Overlap Protection
If an error type or exception class is configured as both retryable and non-retryable, the application fails at startup.
For example, this configuration is rejected:
SelectiveRetryPolicy.<ApplicationException, ErrorType>builder()
.retryOnErrorType(ErrorType.SERVICE_SERVER_ERROR)
.doNotRetryOnErrorType(ErrorType.SERVICE_SERVER_ERROR) // Illegal
.build();
Misconfiguration is treated as a configuration error — not a runtime surprise. The actual policy is here
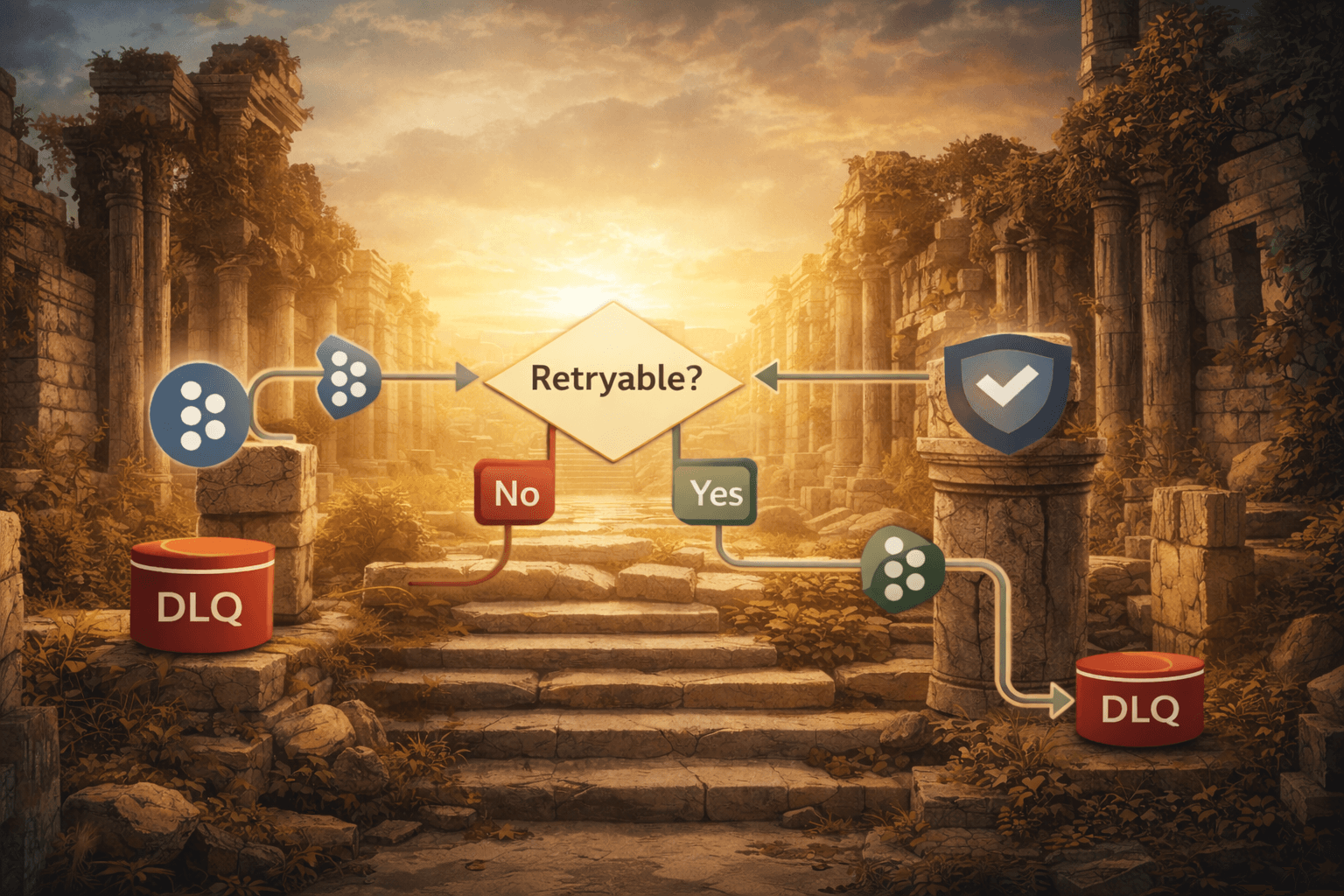
Precedence Model
The evaluation order is explicit:
1. Typed exception error type rules
└── Explicitly non-retryable → do not retry
└── Explicitly retryable → retry
└── Otherwise → fall through
2. Exception class rules
└── Explicitly non-retryable → do not retry
└── Explicitly retryable → retry
└── Otherwise → default
3. Default behaviour → retry
Non-retryable rules always take precedence.
If no rule matches, the policy defaults to retry.
This is intentional and can be flipped if a fail-safe approach is preferred.
Usage Example 1 — REST Client
Define the retry template once:
@Bean("serviceRetryTemplate")
public RetryTemplate serviceRetryTemplate() {
var policy = SelectiveRetryPolicy.<ApplicationException, ErrorType>builder()
.maxAttempts(3)
.typedExceptionClass(ApplicationException.class)
.errorTypeExtractor(ApplicationException::getType)
.retryOnException(SocketTimeoutException.class)
.doNotRetryOnErrorType(ErrorType.VALIDATION_ERROR)
.doNotRetryOnErrorType(ErrorType.SERVICE_CLIENT_ERROR)
.build();
var backOff = new ExponentialBackOffPolicy();
backOff.setInitialInterval(1000L);
backOff.setMultiplier(2.0);
backOff.setMaxInterval(10000L);
RetryTemplate template = new RetryTemplate();
template.setRetryPolicy(policy);
template.setBackOffPolicy(backOff);
return template;
}
Option A — Explicit RetryTemplate
@Service
public class TrackingServiceClient {
private final RestTemplate restTemplate;
private final RetryTemplate retryTemplate;
public TrackingDTO getTracking(String shipmentId) {
return retryTemplate.execute(ctx ->
restTemplate.getForObject("/tracking/{id}", TrackingDTO.class, shipmentId)
);
}
}
This makes retry behaviour visible at the call site.
Option B — Declarative via @Retryable
@Bean("selectiveRetryInterceptor")
public RetryOperationsInterceptor selectiveRetryInterceptor() {
RetryOperationsInterceptor interceptor = new RetryOperationsInterceptor();
interceptor.setRetryOperations(serviceRetryTemplate());
return interceptor;
}
@Service
public class TrackingServiceClient {
private final RestTemplate restTemplate;
@Retryable(interceptor = "selectiveRetryInterceptor")
public TrackingDTO getTracking(String shipmentId) {
return restTemplate.getForObject("/tracking/{id}", TrackingDTO.class, shipmentId);
}
}
The retry contract remains centralised.
The annotation simply references it.
Usage Example 2 — Kafka Producer
Kafka introduces its own mix of transient and permanent failures.
@Bean("kafkaRetryTemplate")
public RetryTemplate kafkaRetryTemplate() {
var policy = SelectiveRetryPolicy.<ApplicationException, ErrorType>builder()
.maxAttempts(3)
.typedExceptionClass(ApplicationException.class)
.errorTypeExtractor(ApplicationException::getType)
.retryOnException(KafkaException.class)
.retryOnException(NetworkException.class)
.retryOnException(RetriableException.class)
.doNotRetryOnException(SerializationException.class)
.doNotRetryOnException(RecordTooLargeException.class)
.doNotRetryOnException(InvalidTopicException.class)
.doNotRetryOnErrorType(ErrorType.VALIDATION_ERROR)
.build();
var backOff = new ExponentialBackOffPolicy();
backOff.setInitialInterval(2000L);
backOff.setMultiplier(2.0);
backOff.setMaxInterval(30000L);
RetryTemplate template = new RetryTemplate();
template.setRetryPolicy(policy);
template.setBackOffPolicy(backOff);
return template;
}
Apply it transparently using a proxy:
@Bean
public BeanNameAutoProxyCreator notificationProducerProxy() {
BeanNameAutoProxyCreator creator = new BeanNameAutoProxyCreator();
creator.setBeanNames("notificationsProducer");
creator.setInterceptorNames("kafkaRetryInterceptor");
return creator;
}
Producer remains clean:
@Service("notificationsProducer")
public class NotificationsProducer {
private final KafkaTemplate<String, Object> kafkaTemplate;
public void publish(String topic, Object message) {
kafkaTemplate.send(topic, message);
}
}
Why This Exists (Preventative Design)
The motivation here was not a dramatic outage.
It was to prevent two quiet failure modes from creeping in over time:
Missed retries — transient failures wrapped in generic exceptions that never get retried.
Over-retries — permanent failures retried repeatedly because the policy cannot distinguish them.
Both come from retry logic that lacks semantic awareness.
This pattern removes that ambiguity.
The Trade-off
This approach shifts responsibility to the throw site.
If an error is classified incorrectly, retry behaviour will also be incorrect.
That is deliberate.
Inferring retry intent from HTTP codes or exception messages tends to become brittle and distributed.
Encoding intent explicitly at the throw site keeps retry behaviour centralised and predictable.
Closing Thoughts
Retries are not a technical detail.
They are part of system behaviour.
A retry policy that does not understand failure semantics is not resilience.
It is optimism with overhead.
Spring Retry provides the foundation.
Adding a semantic layer on top makes retry behaviour readable, auditable, and difficult to misconfigure.
In a multi-service codebase, that clarity is usually the difference between retry logic you trust and retry logic you tolerate.