When Consumers Fail: Extending Selective Retry to Kafka
Resilient Consumers, Happy Applications!
Designing a Kafka Error Pipeline
Kafka consumers fail for the same reason every distributed component fails: not all errors mean the same thing.
A network timeout, a malformed payload, and a downstream outage are all failures — but treating them the same leads to the same bad outcomes: wasted retries, stalled partitions, and messages cycling through retry loops that were never going to succeed.
Most Kafka consumer setups do exactly that: they retry everything until a limit is reached and only then decide what to do with the message.
That works — until it doesn't.
In the previous post, Not All Failures Deserve a Second Chance, the focus was classification: a typed exception carrying an ErrorType, and a retry policy that understands the semantics of failure instead of guessing from exception classes.
That article covered the outbound side of a system — REST clients, Kafka producers, and service calls.
This post moves to the other side of the boundary: the Kafka consumer pipeline.
The classification already exists.
The retry policy already exists.
What remains is shaping the consumer pipeline so it respects those decisions.
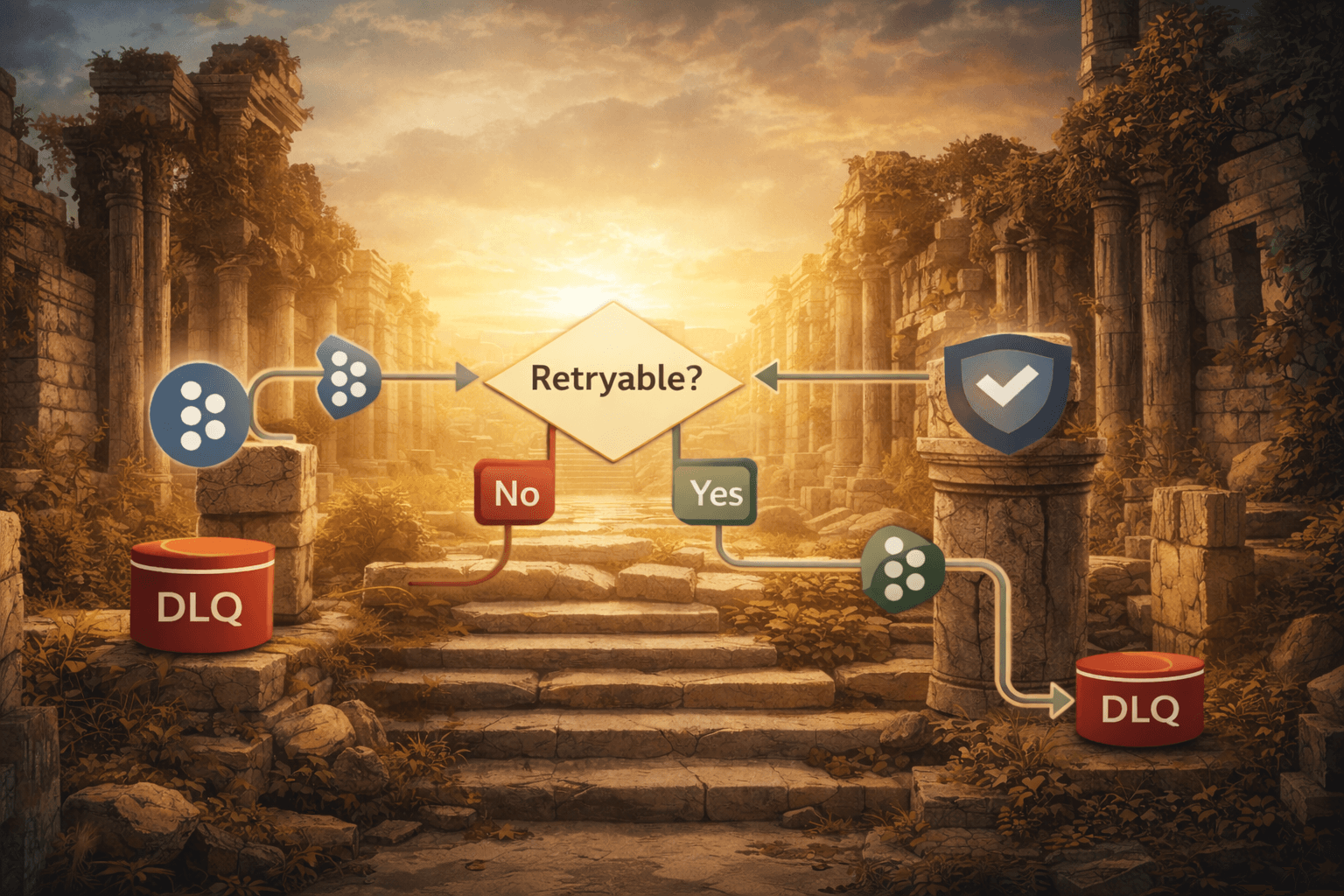
Consumer Failure Pipeline
Before looking at the code, it helps to picture the error flow at a system level.

The diagram shows how a consumer failure is classified and how that classification determines the routing path.
Two decisions drive the entire pipeline:
Is the failure retryable?
This is decided once by theSelectiveRetryPolicy, which classifies the error according to its semantics (transient vs. permanent, etc.).If retries exhaust, where does the message go next?
That routing decision is determined by configuration (for example: retry topic, dead-letter topic, parking lot, or discard).
Separating classification from routing keeps the error-handling logic predictable: classification happens once, and subsequent routing behaviour follows from that classification and your configured policies.
What DefaultErrorHandler Doesn't Do
Spring Kafka's DefaultErrorHandler retries up to a configured limit and routes to a recoverer on exhaustion.
That behaviour is useful — but it applies the same retry loop regardless of why the record failed.
A VALIDATION_ERROR receives the same retry attempts as a transient SERVICE_SERVER_ERROR. Those retries accomplish nothing. The payload will not change between attempts. The only effect is that the partition is blocked while the consumer repeatedly processes something it already knows will fail.
DefaultErrorHandler does not decide whether something should be retried.
It simply retries.
The solution is to place a handler in front of it that decides whether the record should enter that retry loop at all.
CompositeKafkaErrorHandler
When a Kafka consumer throws, Spring invokes handleOne() on the configured CommonErrorHandler — in most apps this is DefaultErrorHandler. CompositeKafkaErrorHandler wraps that handler and introduces one additional decision point before delegating.
It composes three things:
a
SelectiveRetryPolicy(from the previous article)a recoverer for retryable errors whose retries are exhausted
a recoverer for non‑retryable errors
The two recoverers represent different outcomes: a transient error that exhausts retries and a validation/semantic failure are both routed somewhere observable, but they should not reach that destination in the same way or at the same time in the flow.
public class CompositeKafkaErrorHandler<T extends Throwable, E extends Enum<E>>
implements CommonErrorHandler {
private final DefaultErrorHandler defaultErrorHandler;
private final SelectiveRetryPolicy<T, E> retryPolicy;
private final BiConsumer<ConsumerRecord<?, ?>, Exception> exhaustedRecoverer;
private final BiConsumer<ConsumerRecord<?, ?>, Exception> nonRetryableRecoverer;
public CompositeKafkaErrorHandler(
SelectiveRetryPolicy<T, E> retryPolicy,
BackOff backOff,
BiConsumer<ConsumerRecord<?, ?>, Exception> exhaustedRecoverer,
BiConsumer<ConsumerRecord<?, ?>, Exception> nonRetryableRecoverer) {
this.retryPolicy = retryPolicy;
this.exhaustedRecoverer = exhaustedRecoverer;
this.nonRetryableRecoverer = nonRetryableRecoverer;
this.defaultErrorHandler = new DefaultErrorHandler(
(record, ex) -> exhaustedRecoverer.accept(record, ex),
backOff);
}
// ... delegate handleOne() to defaultErrorHandler after consulting retryPolicy ...
}
The generics mirror the retry policy: <T extends Throwable, E extends Enum<E>>.
Importantly, the handler is policy-driven: it doesn't depend on ApplicationException or an ErrorType enum directly. It only asks the SelectiveRetryPolicy whether a failure is retryable and routes accordingly, keeping the handler reusable across services with different exception hierarchies.
Routing the Failure
handleOne() performs the routing.
@Override
public boolean handleOne(Exception thrownException, ConsumerRecord<?, ?> record,
Consumer<?, ?> consumer, MessageListenerContainer container) {
// Deserialization failures occur before business logic runs.
if (thrownException.getCause() instanceof DeserializationException) {
nonRetryableRecoverer.accept(record, thrownException);
commitOffset(record, consumer);
return true;
}
// Ask the retry policy first.
if (isNonRetryableError(thrownException)) {
nonRetryableRecoverer.accept(record, thrownException);
commitOffset(record, consumer);
return true;
}
// Retryable → delegate to DefaultErrorHandler
return defaultErrorHandler.handleOne(thrownException, record, consumer, container);
}
The first branch handles deserialization failures.
These occur before business logic runs, meaning the typed exception hierarchy is not involved. DeserializationException.getData() contains the raw bytes of the message. Those bytes must be preserved and sent somewhere observable before the record is skipped.
Silently dropping malformed messages means you have no record that they ever arrived.
The second branch asks the retry policy whether the failure is non‑retryable. The policy evaluates the typed error classification first and falls back to exception‑class rules if necessary.
Non‑retryable failures skip the retry loop entirely.
The record is routed to the non‑retryable recoverer and the offset is committed at offset + 1. This tells Kafka the record has been handled and the consumer should move forward.
Because this path bypasses DefaultErrorHandler, the handler must also take responsibility for committing the offset itself.
Without that commit the consumer would stall on the same record indefinitely.
If neither branch matches, the exception is considered retryable and DefaultErrorHandler takes over using the configured BackOff.
When retries are exhausted, the recoverer wired into the constructor invokes exhaustedRecoverer.
Recoverers Belong in Configuration
The handler is infrastructure. It understands how to route failures but not where they should go.
Destination policy belongs in configuration.
CompositeKafkaErrorHandler therefore accepts two BiConsumer<ConsumerRecord<?, ?>, Exception> functions:
BiConsumer<ConsumerRecord<?, ?>, Exception> exhaustedRecoverer = (record, exception) ->
{
if (retryProperties.isEnabled()) {
errorPublisher.publishToRetry1m(record, exception);
} else {
ApplicationException appEx = exception instanceof ApplicationException ae ? ae: ApplicationException.of(ErrorType.SERVICE_SERVER_ERROR, "Retries exhausted: " + exception.getMessage());
errorPublisher.publishToDlq(record.topic(), record.value(), appEx, record);
}
};
BiConsumer<ConsumerRecord<?, ?>, Exception> nonRetryableRecoverer = (record, exception) ->
{
if (exception.getCause() instanceof DeserializationException) {
errorPublisher.publishDeserializationFailureToDlq(record, exception);
} else {
errorPublisher.publishBatchRecordToDlq(record, exception);
}
};
return new CompositeKafkaErrorHandler<>(kafkaConsumerRetryPolicy, backOff, exhaustedRecoverer, nonRetryableRecoverer);
The handler remains reusable across services.
Only the routing behaviour changes — which DLQ topic to use, whether retry topics are enabled, or how generic exceptions should be wrapped..
The Retry Chain
In‑process retries are designed for milliseconds of instability, not minutes of outage.
They handle short‑lived issues such as network jitter or brief service hiccups. They do not solve problems like dependency restarts, rate limits that reset on minute boundaries, or a database mid‑failover.
For those situations the message needs time.
When in‑process retries exhaust on a retryable error, the record is moved to a separate Kafka topic instead of going directly to the DLQ.
A dedicated consumer processes source-topic-retry-1m, waiting at least one minute before redelivery. If retries exhaust again, the message progresses to source-topic-retry-5m, and finally to the DLQ if all stages fail.
Non‑retryable failures bypass this chain entirely.
A validation error that occurs at 10:00:00 should be visible in the DLQ at 10:00:00 — not at 10:06:00 after exhausting retry stages it had no reason to enter.
The chain is controlled through configuration:
kafka:
retry:
enabled: ${KAFKA_RETRY_ENABLED:true}
suffixes:
first-stage: ${KAFKA_RETRY_1M_SUFFIX:retry-1m}
second-stage: ${KAFKA_RETRY_5M_SUFFIX:retry-5m}
error:
dlq-suffix: ${KAFKA_DLQ_SUFFIX:-dlq}
Setting kafka.retry.enabled=false routes exhausted retryable errors directly to the DLQ in environments that do not provision retry topics.
What is not optional is the DLQ itself.
A consumer that silently drops failed records has no observable error signal.
One Classification, Two Contexts
The SelectiveRetryPolicy driving CompositeKafkaErrorHandler is the same policy used for outbound retries.
The failure taxonomy is defined once.
Whether VALIDATION_ERROR should be retried is not a decision repeated in HTTP clients, Kafka consumers, and service calls. The behaviour follows directly from the ErrorType definition.
Add a new ErrorType variant with the correct semantics and it automatically receives the right behaviour everywhere — inbound and outbound.
That is what it means for retry logic to be readable and auditable.
Not just in one place.
Across the system.